Wprowadzenie
POOL na tle podobnych narzędzi na świecie; nasze motywacje i źródła pomysłów; dalszy rozwój języka.
- Dialekty LOGO.
- Do czego dziś służą języki w stylu LOGO.
- Co nowego może wnieść kolejny dialekt?
- POOL – Parallel Object Oriented LOGO.
- Plany na przyszłość.
1. Dialekty LOGO.
Język LOGO stworzony został w 1967r z myślą o celach edukacyjnych – do nauki programowania na poziomie szkolnym.
Język LOGO, w swoim pierwowzorze wywodzący się z języka LISP, nie posiada precyzyjnej specyfikacji. Dziś
istnieje wiele odmian, zachowujących podobną składnię i nazwy podstawowych instrukcji. Ich wspólną, powszechnie
rozpoznawaną cechą jest implementacja grafiki żółwia – obiektu rysującego na ekranie przy pomocy
przesunięć, obrotów, itp., które interpretuje względem swojego położenia. Poszczególne dialekty LOGO pozwalają
na tworzenie programów o różnym stopniu złożoności, a niektóre z nich są rozwijane dla dedykowanych zastosowań.
Zestawienie rodowodów i powiązań dialektów można znaleźć np.
tu.
Tworząc POOL chcemy wzbogacić język LOGO o nowoczesne elementy, ale zarazem pozostać w tzw. „głównym nurcie”
dialektów LOGO. Opieramy się więc na uznanych w społeczności LOGO rozwiązaniach. Jednym z takich punktów
odniesienia jest Berkeley Logo, znane też pod nazwą UCB Logo (i jego sukcesor: FMS Logo).
Znacząca większość zasad składni tego dialektu jest zgodna z POOL. Wprowadzając reguły definiowania klas
wzorowaliśmy się na dialekcie Elica – minimalistyczne zasady tego dialektu są intuicyjne dla
początkujących i dobrze pasują do natury LOGO.
W zaawansowanych zastosowaniach obserwujemy rozwój NetLogo, które dedykowane jest przede wszystkim
symulacjom wieloagentowym. Jednak NetLogo jest mniej związane z głównym nurtem LOGO; różni się także od
POOL brakiem możliwości programowania obiektowego oraz w wielu „wewnętrznych” rozwiązaniach.
2. Do czego dziś służą języki w stylu LOGO.
LOGO i jego pochodne można bardzo ogólnie zaklasyfikować do szerokich obecnie kategorii języków wysokiego
poziomu i języków skryptowych. Dwa główne obszary zastosowań języków z rodziny LOGO to:
-
Edukacja – nie tylko w nauce programowania (wg UE: ICT practitioner skills), ale także jako
narzędzie w poznaniu nauk przyrodniczych na wielu poziomach zaawansowania (ogólnie: ICT user skills).
Obecną sytuację w Polsce na tle innych krajów opisują raporty:
2013,
2014.
Co ciekawe, rola edukacyjna rozciąga się na rozwój kreatywności nie tylko w naukach ścisłych – co można
prześledzić m.in. w materiałach konferencji takich jak Constructionism.
-
Środowiska do symulacji i wizualizacji procesów, modelowania wieloagentowego i analizy danych,
umożliwiające szybką implementację algorytmów. Są to narzędzia do rozwiązywania problemów na poziomie
akademickim.
Warto zauważyć, że w obu zastosowaniach często są stosowane te same narzędzia. Takie wykorzystanie inwestycji
w naukę jest siłą języków LOGO i było dla nas ważnym czynnikiem w wyborze podstaw projektu POOL.
3. Co nowego może wnieść kolejny dialekt?
Grafika żółwia związana z językiem LOGO doskonale ilustruje sens programowania obiektowego: „żółw”-obiekt
posiada własne atrybuty i może wykonywać dedykowane polecenia. W niektórych dialektach (np. Elica)
możliwe jest jawne stosowanie elementów klasycznego programowania obiektowego, czyli tworzenie złożonych typów
danych: klas. W wielu dialektach „obiektowość” oznacza jedynie możliwość istnienia obiektów o specjalizowanych
atrybutach czy też możliwość wywołania instrukcji w kontekście predefiniowanych obiektów.
Naturalne dla LOGO jest umożliwienie istnienia populacji obiektów (agentów) oraz sterowanie ich jednoczesnym
działaniem. Ta cecha jest podstawą np. NetLogo, które jednak jako język programowania jest bardzo
uproszczone.
POOL łączy obiektowość i równoległość. Chcemy by język pozwalał na możliwie naturalny opis równoległych
algorytmów; techniczna realizacja zadań (uruchomienie wątków obliczeń, synchronizacja wyników) powinna
angażować programistę w minimalnym stopniu. Aby osiągnąć ten cel konieczne było rozwinięcie w POOL możliwości
programowania obiektowego znacznie szerzej niż w dotychczasowych dialektach LOGO. W POOL pierwszoplanowe są
obiekty aktywne: niezależne procesy, wykonujące zadania we własnych przestrzeniach zmiennych i kodu. Składnia
języka opisuje też sposoby komunikacji obiektów i sterowania nimi. Rozwijamy język w kierunku akcentu na
zestawienie „parallel object”, natomiast „object oriented” jest naturalną konsekwencją.
Charakterystyczna dla LOGO możliwość dynamicznego tworzenia zmiennych i kodu jest rozwijana w POOL w postaci
dynamicznego dziedziczenia oraz dynamicznej ewolucji składowych klas. Chcemy w ten sposób udostępnić ciekawe
możliwości opisu i badania algorytmów adaptacyjnych czy też optymalizacji symbolicznych.
W dialekcie POOL proponujemy dwa modele programowania obiektowego:
-
„standardowy”: klasy są wstępnie zdefiniowane w treści programu i następnie używane do utworzenia
nowego obiektu; hierarchia klas może być zdefiniowana statycznie bądź dynamicznie;
-
„w stylu LOGO”: nowy obiekt potomny dziedziczy z klasy tworzącego go obiektu nadrzędnego;
dynamicznie dodawane zmienne i funkcje w obiektach nadrzędnych są odpowiednio widoczne w obiektach
potomnych.
W obu modelach występuje dziedziczenie z możliwością użycia funkcji wirtualnych. Możliwe jest jednoczesne
wykorzystanie cech obu modeli.
Aby zachować wartość edukacyjną POOL umożliwia płynne przejście od posługiwania się wyłącznie podstawową
składnią LOGO do programowania obiektowego oraz użycia bardziej zwięzłej i abstrakcyjnej składni.
4. POOL – Parallel Object Oriented LOGO.
W wersji POOL 1.0 zaimplementowana została podstawowa funkcjonalność i większość instrukcji używanych w
dialektach zgodnych z głównym nurtem LOGO. Ponieważ nie istnieje standard LOGO, rozumiemy przez to
stwierdzenie, że proste programy przykładowe dostępne w popularnych dziś implementacjach LOGO można uruchomić
w POOL bez modyfikacji lub z kosmetycznymi zmianami. Instrukcje, które pojawią się w kolejnych edycjach POOL
nie wniosą zmian w podstawowe założenia projektu.
POOL obsługuje także zdarzeniowy model programowania. Zdarzeniami mogą być akcje użytkownika (np. zdarzenia w
interfejsie użytkownika, wciśnięcia klawiszy klawiatury) lub sygnały wysyłane „programowo” przez obiekty
działające w programie.
Obiekty aktywne.
Każdy obiekt w POOL posiada własną przestrzeń zmiennych i zdefiniowanych dla niego funkcji. Zgodnie z regułami
dziedziczenia (nieco odmiennymi w obu modelach dziedziczenia) obiekt ma dostęp do zmiennych i funkcji w klasach
bazowych i obiektach nadrzędnych. Obiekty wykonują swoje zadania sekwencyjnie, równolegle z zadaniami innych
obiektów. Zadania są zarządzane (kolejkowane i przekazywane do wykonania w jednym z wątków wirtualnej maszyny)
przez algorytm planowania. Wszystkie obiekty w POOL 1.0 są reprezentowane graficznie przez „żółwie”.
Program w dialekcie POOL jest wykonywany przez obiekt nadrzędny, który może wykonać cały program jako jedno
zadanie lub jako serię zadań, korzystając z wielu możliwych scenariuszy. Obiekt nadrzędny może tworzyć obiekty
potomne, które następnie także mogą tworzyć obiekty potomne. Obiekty są autonomiczne, ale zachowują informację
o hierarchii nadrzędny-potomny, która jest podstawą jednego z modeli dziedziczenia. Instrukcje wydawane w linii
poleceń, podobnie jak funkcje obsługi zdarzeń są traktowane jako odrębne zadania i umieszczane przez algorytm
planowania w kolejce zadań wybranego obiektu.
Przykład:
to fn :x
if :x < 1 [output 0]
output :x + fn :x - 1
end
to onmouseclick :mousepos
print :mousepos
end
"lista := []
"t := (anewt [print "konstruktor])
for [i 1 3] [
queue :lista (fn :i) @ :t
]
print :lista
Rezultat wykonania:
konstruktor
[1 3 6]
{30 15}
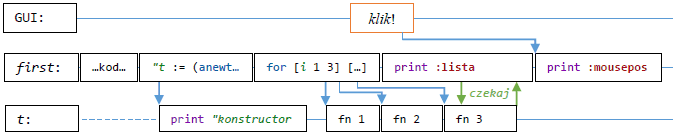
Przykład ilustruje planowanie i wykonanie zadań w prostym programie. Każdy program jest uruchamiany jako
zadanie głównego obiektu: first, który może tworzyć obiekty potomne (w tym przypadku
t). Obiekty wykonują swoje zadania sekwencyjnie. Zdarzenia (np. kliknięcia myszą)
uruchamiają funkcje obsługi, które są umieszczane w kolejkach zadań.
Uwagi do punktów zaznaczonych w kodzie:
-
Funkcja obsługi zdarzenia. Jest rozpoznawana przez swoją nazwę i domyślnie włączona dla obiektu,
który zawiera jej definicję. Funkcja jest również dostępna dla obiektów potomnych, ale obsługa
zdarzenia jest domyślnie wyłączona.
-
Kod konstruktora (który w POOL w pełni definiuje również klasę obiektu) może być przekazany
bezpośrednio do instrukcji
anewt.
-
Funkcja
fn wywołana dla obiektu t. Wywołania
powodują utworzenie zadań dla t, podczas gdy first
może kontynuować swój program. Wyniki wywołań funkcji są zapisywane w zmiennej lista
w formie obietnic.
-
Wypisanie zmiennej
lista w oknie tekstowym jest zawieszane, gdy napotyka nie
zrealizowaną jeszcze wartość obietnicy.
Cechą wyróżniającą POOL jest kompilacja programów do kodu CIL (Common Intermediate Language
wykonywany na platformie .NET). Pozwala to znacznie zwiększyć wydajność programów w stosunku do dialektów LOGO
interpretujących kod. Jest to niebagatelna korzyść nawet dla początkującego programisty – jakość pracy i
satysfakcja są znacząco różne kiedy kod wykonuje się 10-20 razy szybciej.
Pewnym wyzwaniem była dla nas implementacja kompilatora dla języka zwyczajowo interpretowanego, umożliwiającego
dynamiczne generowanie kodu oraz uruchamianie kodu w "linii poleceń" w trakcie działania programu. Dodatkowo,
w dialekcie POOL zaplanowaliśmy obiektowość i funkcje wirtualne. Obecnie wydajność kodu wynikowego tworzonego
przez narzędzia POOL jest porównywalna z innymi (często o wiele prostszymi) dialektami kompilowanymi. Dla
edycji 1.1 zaplanowaliśmy już algorytmy kompilacji, które pozwolą na znaczny skok wydajności.
5. Plany na przyszłość.
POOL jest na etapie wersji 1.0. Testy "przedpremierowe" zweryfikowały użyteczność wielu elementów języka.
W następnych edycjach będziemy kontynuowali tryb częstych aktualizacji, pozwalający szybko udostępniać
nowe elementy – zarówno w środowisku uruchamiania programów jak i w samym języku.
Główne kierunki, w których będziemy zmierzali to:
- grafika i prezentacja danych;
- komunikacja z zewnętrznym światem: dostęp do źródeł danych i urządzeń, współpraca z zewnętrznymi
bibliotekami kodu;
- optymalizacja wydajności kodu wynikowego.
POOL ma duży potencjał, jednak szczegóły projektowanych zmian na razie pozostają tajemnicą.